


{kind=link}
As businesses move to offer online services, new digital streams are created from vast customer-business touch points. These modern systems create data with a different format compared to what legacy systems have been creating. Thus, the emergence of unpredictable data formats requires a shift in the usual paradigm of data engineering.
This article explains the evolution of data engineering from using ETL to the ELT process. You will know the key difference in their purpose of use and evaluate the best technique for a required analytical process.
It all started with ETL
ETL is defined as the engineering process that transforms batch uploads and stream data in a usable format. The transformation of data is critical to the analysis in the presentation layer using Business Intelligence- BI tools. There are three major tasks of an ETL pipeline: extract, transform, and load.
From organizational sources such as ERP, CRM, and billing systems, data is extracted to a staging area. Here transformations such as filtering, masking for security, enrichment with external data, cleansing errors, standardizing data types, and integration from all sources is performed. The result is a rigorous data structure that offers a clean and clear repository.
In the loading stage, again a structure for data is created specifically to answer the most selective business queries with quick response time. Learn more about ETL and data pipelines in this comprehensive guide.
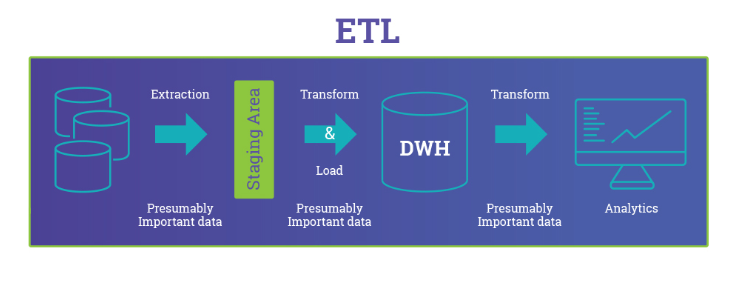
Keeping this in mind, you can now conclude that ETL enables highly structured data arrangement within a data warehouse. And so, a data warehouse is built on the assumption that you must know which business questions to answer before starting with ETL. It’s a schema fixed approach.
ETL approach fails in today’s modern data analytics landscape where new sources of data have become critical for business reporting and analysis and is unstructured in nature.
While clearly, adding new business dimensions into already established data model is not easy. It requires engineering a new data pipeline with a new schema which is a highly resource-intensive task. Moreover, semi-structured or unstructured data contains undefined entries that are removed while parsing data from unstructured to structured format.
Rise of ELT
ELT systems offer robust data ingestion from newer systems such as sensors from IoT systems, data from social media, weblog data from websites, and mobile usage data from SaaS apps. All these sources use machine generated data that lacks structured format.
To compensate for this new class of data sources, the solution is to engineer a flexible data pipeline that transforms data into desired schemas. This will offer more perspective to business data by ensuring that required information is not lost. The new data pipeline is called ELT where the letters L and T in earlier ETL are swapped with each other. The term ELT corresponds to ‘Loading’ before ‘Transformation’.
Data science and machine learning workloads often require data in raw form because their data analysis needs are not known beforehand. Data scientists explore the raw data and then determine the way in which data needs to be converted into information.
After extraction of the schemaless data, the data is simply loaded to a noSQL ‘Hadoop’ technology such as ‘data lake’. This technology is specifically designed to contain any kind of raw data and acts as a centralized data repository. The ingestion process is much faster than ETL process since now the transformation stage is not required after extraction.
The transformation stage carries out the tasks such as cleansing, formatting, deduplicating, masking, and filtering as required by the Data scientist. Note that, at this point, data analysts can also build schemas on structural data can also be performed for downstream analysis.
The flexibility in building schemas as per the requirement of a Data scientist allows for deeper analysis and thus creates a modern analytics system for today’s organizations.

When to consider ELT?
The old legacy ETL is perfect when there’s structured data from OLTP databases and other legacy systems such as ERP, CRM, and SRM etc., On the other hand, when there’s machine generated data from IoT systems, SaaS applications, social media, and weblogs, the system fails.
You can remember these basic rules to know when to prefer ELT or ETL.
- Use ETL when there’s structural data. ETL could also be used when there’s semi-structural data whose ‘structured elements’ could help in analysis
- Use ELT when there’s semi-structured or completely unstructured data and enable rich analytics by transforming the undefined data types into ‘variant data types’
IMPORTANT: Many organizations use a data warehouse and data lake together to enable both data warehousing and data science applications.
PS: As a next step in your learning, it’s advisable to learn about Teradata and Snowflake’s approach towards enabling analytics with semi structured data.