


{kind=link}
Of the few technology companies dominating the global analytics market, Teradata and Snowflake are one of them. In this article, we explore in detail, the two market leading data warehouse solutions. You will learn the key technological differences that will help you to choose the best solution for your future application.
Teradata
Teradata Vantage aka Teradata is a data warehouse technology that offers flexible warehousing services. These services are available from on-premise to multi-cloud data platforms. Teradata has a highly scalable relational database management system (RDBMS) suitable for workload-intense data warehousing applications.
According to Gartner 2020 Magic Quadrant, Teradata has been recognized in the LEADERS category in the analytics industry. It has a highly advanced approach to support data lakes, data warehouses, and new data sources, and types.
Some unique features of Teradata are:
Massive Parallel Processing
Teradata breaks workload among multiple parallel processing elements called AMPs. These processing elements also act as permanent data stores. Also known as the Massively Parallel processing- MPP, it aims to support fast query processing multiple synchronous users. There are 3 to 36 AMPs within a node.
Scalability
Teradata offers its processing nodes to be increased linearly (given its shared-nothing architecture) as required by the user. Teradata can offer users to scale up to a maximum of 2048 processing nodes.
Usage Flexibility
Teradata is available for hybrid environments where you are to choose between on-premises through Teradata IntelliFlex or a cloud platform such as Azure, Google Cloud, and AWS. Interestingly it also allows deployment on commodity hardware using VMware.
Snowflake
Snowflake is a fully-managed, SaaS platform that offers a ‘cloud-only’ data platform. It’s not built on existing ‘databases’ or ‘big data’ technologies. Instead it relies on its own SQL query engine and builds a single unique data architecture. Therefore, it supports all analytics technologies including data warehouse, data lake, and data science.
In Snowflake data space, there’s no distinction between RDBMS or non-RDBMS solutions as it can ingest both structured and semi-structured data.
Gartner recognizes Snowflake in the CHALLENGERS category in it’s 2020 magic quadrant of the analytics industry.
Some unique features of Snowflake are:
Massive Parallel Processing
Snowflake also uses MPP while processing queries. However, the data is stored at a physically separate location that’s a centralized repository. The queries are processed on ‘virtual warehouse’ (also called cluster), and depending on query workload, upto 10 clusters could be assigned.
Structured and semi-structured data support
Snowflake has a patented approach that lets it to read semi-structured data and store it in it’s data warehouse.
Software-as-a-service
Snowflake is a SaaS platform which means that you only apply for Snowflake’s service, and provide them with data. The next administrative steps are governed by Snowflake’s AI technology that precisely processes your tasks.
Scalability
Like Teradata, Snowflake too offers high scalability but the way it’s achieved is different. Snowflake achieves scalability from its ‘Multi-cluster architecture’.
Head-to-head comparison: Teradata vs. Snowflake
This section will detail the key differences in the two data warehouse technologies along the dimensions of: Database architecture, support for semi-structured data, and single source for all business data.
Database Architecture
Teradata’s ‘Shared-nothing’ Architecture
Teradata is based on ‘shared-nothing’ database architecture. It’s a database design that carries a number of parallel databases each containing its own components assembly such as processor and memory.
The term Massively Parallel Processing- MPP is also used to refer to the parallel working of processors within the database space.
As opposed to shared-nothing architecture, a shared-disk architecture uses a centralized database that’s accessible, as a whole, to all the compute nodes. Shared-disk architecture is simple and easy to implement, however it lacks scalability due to limitations in access when a huge number of users try to access the shared database.
Data coming from the source system, a landing server in case of Teradata, is distributed across the vast parallel processors called the AMPs. These AMPs have their own compute and storage capacity and use them independently of neighboring AMPs. Data chunks are stored in the permanent space of each AMP, whereas a ‘spool space’ which is a Teradata term, is preserved for query processing over the same data.
With shared-nothing architecture, it becomes easy to scale up and down compute and storage as required by the user application. However, the challenge of using such an approach lies in the distribution of data across the nodes each time scaling is required. This additional overhead affects the performance of the system and is not practical.
Another challenge lies in the ‘balance of compute and storage’. In a shared-nothing architecture, there’s a high chance that the computation storage might be more, or insufficient for query processing. Teradata divides the workload evenly among the AMPs, however, it actually depends on the query how much computation it will require on the AMPs.
Snowflake’s ‘Hybrid’ Architecture
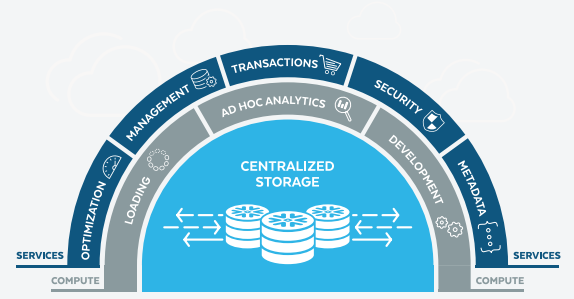
Snowflake, which emerged after Teradata, had an eye on all these issues. It found a way to overcome the limitations of database architecture that emerged in both the shared-nothing and shared-disk architectures. Unlike Teradata, Snowflake keeps data storage and computation physically separate. Doing this, Snowflake aims to combine the benefits of shared-nothing and shared-disk architectures and overcome their limitations.
Given the above, Snowflake stores data on a central repository in ‘data storage layer’ and grants access to part of it to the MPP compute clusters. These clusters are also called ‘virtual warehouses’ and reside in the ‘query processing layer’. The unique ability of these virtual warehouses to optimize access to the central database makes it overcome the scalability issue in ‘shared-disk architecture’.
Moreover, the on-spot distribution of data, as the query is initiated by the user, allows dynamic usage of compute sources. This happens to achieve the desired balance in compute and storage. Each virtual warehouse is sized on-spot as per the complexity of the query.
Handling Semi-structured data
Teradata doesn’t store semi-structured data into its data warehouse optimized strictly for relational rows and columns. Instead, Teradata allows users to read semi-structured data such as CSV, JSON, and XML files from an object store external to the Teradata warehouse. Users can query this semi-structured data, use it for analysis with Teradata’s structured data, and write back data into external object storage. Teradata offers such functionality with its service of ‘Native Object Store’.
The data warehouse of Snowflake is unique in this way as it allows storage of semi-structured data alongside conventional structured format. Doing this is a formidable task since the non-relational data such as semi-structured data doesn’t have a fixed schema and may change regularly.
Snowflake uses its patented approach in storing semi-structured data into its relational database. It captures the repeated attributes in semi-structured data and combines similar-category data separately. This data could be queried later using extended SQL for analysis with structured data.
Single System for All Business Data
Having the ability to process unstructured data is a holy grail. According to statistics, almost 80% of today’s organizations produce unstructured data. To leverage useful information from this data, organizations design separate database architectures for storing structured and semi-structured data. This introduces siloed business data and needs an additional step of integration. This ultimately hinders a cost-effective and efficient analytics system.
As discussed before, Teradata also needs organizations to set up an external object based data store to store their unstructured data. This data is then accessed using Teradata’s Native Object Store using SQL queries and combined in analysis with structured data in Teradata’s data warehouse.
Snowflake offers better flexibility in this area by enabling a single database architecture for any data. Organizations can truly set themselves free from silos in Snowflake’s data warehouse solution.
Comparison Table
| Feature | Teradata | Snowflake |
| Service | Hybrid: Cloud and on-premise | Cloud only |
| Database Architecture | Shared-nothing | Hybrid: Shared-nothing and shared-disk |
| MPP: Data distribution speed | Fast | Faster |
| Scalability | High | Higher |
| Storage Capacity | Fixed: requires re-distribution after scaling | Dynamic: can be changed on-spot |
| Data Silos | Controlled | Better controlled |
| Database type | RDBMS | RDBMS |
| Fully Managed | Optional | Yes |
| Price | Pay as you go | Pay as you go |
Stating the above differences, now it’s your turn to evaluate what sort of features your application will benefit from. Evaluate your choice by asking these questions:
Does your application requires huge scalability demands in future?
Would you want fully managed services or just the data warehouse resources?
Will you process lots of semi-structured data for your analytics tasks?
What’s your budget requirement?
All these questions will lead you to a warehousing solution that’s best suited for your application.