{kind=link}
Data warehouses and data lakes exist as separate systems in organizations with their own requirements of data architecture. Today, as data architects follow the same convention, Snowflake makes things simpler and more efficient by adopting an innovative approach of a unified data architecture for both technologies.
In this article, we provide an in depth overview on how data architecture has evolved over time from using data marts in data warehouses to adoption of data lakes for big data and finally a unified platform that combines advantages of both.
Data architecture is the backbone of any data analytics technology. To understand Snowflake’s approach towards a unique data architecture, it’s important to understand what data architecture is and how it differs from simple data modeling.
What’s Data Architecture?
Data architecture is a discipline of data management that documents the data assets of an organization. It’s a complete data management guideline. More specifically it handles:
- Types of data to ingest
- Storage system (relational database, noSQL, big data frameworks, or cloud based object database)
- Infrastructure of the platform (either cloud or on-premise)
- Data cleaning and transformation
- Data users and their scope of data access
- Data modeling in application layer for BI reporting and data analytics
- Data security
- Data governance policies
Simply stated, Data Architecture comprises “models, policies, rules, and standards that guide collection, storage, arrangement, integration, and usage of data within an organization”, as viewed by CIO’s Thor Olavsrud .
While data architecture supports data governance for operational processing, it’s there more prominently to define a data environment for BI and advanced analytics initiatives.
Data modeling is also a discipline of data management but adopts a more ‘focused view’. It specifically deals with how data is stored in a repository so that optimal database performance could be achieved. Without making a data model, updating data and using it for analytical processing is erroneous.
Traditional vs. Modern Data Architecture
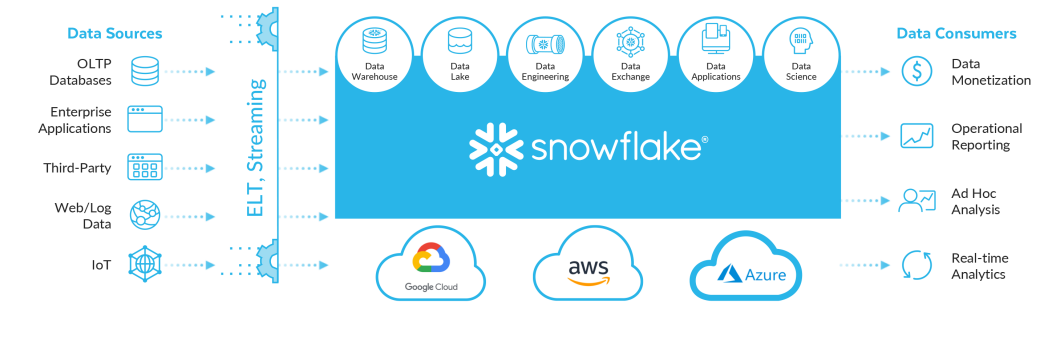
Today, Snowflake has emerged as an innovative data brand after years of dominance by the traditional data warehouse and data lake technologies. The strategy which Snowflake adopted in the design of its data architecture is different from what Data Warehouses and Data lakes have been using.
From Operational System to Data warehouse
Over 20 years ago, companies used relational databases for storage and reporting of their business operations. These databases are the operational systems that were initially intended for data storage. Databases worked fine for querying small data, but as the data grew, data analysts found it almost impossible to perform BI operations due to vast query processing issues.
Data architects soon moved towards a data warehouse solution specifically designed for rigorous query processing to support BI operations. It’s a central repository of data that contains all business data, cleaned, and organized for storage and processing.
However, the warehouse also couldn’t scale to the variable workloads from large number of business units especially when the system was also busy in ingesting the scheduled data. Moreover the access time of users overlapped due to high concurrency demand.
Data marts and problem of Silos
To avoid concurrent users accessing the same information simultaneously, small databases called data marts were used within the warehouse to facilitate business units across the organization. The data warehouse architecture is shown in the figure below.
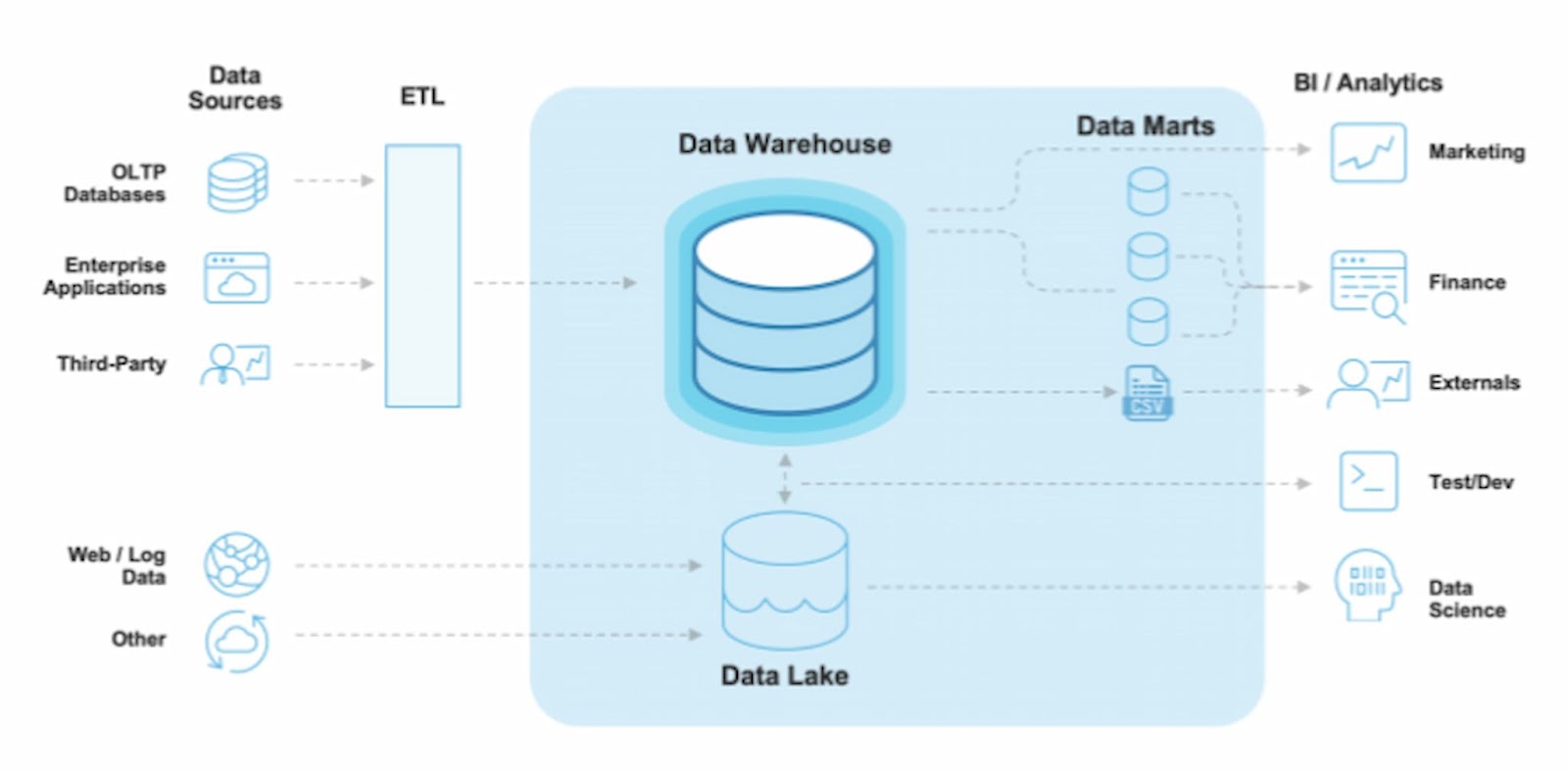
Although data marts saved the concurrency issues, with time, the data architects realized the ‘Data Silos’ in organization. With an inefficient data mart management strategy, these silos caused precarious problems such as:
- Incomplete datasets in data marts
- Inconsistent data among different departments
- duplication of data and processes
- Wanning collaboration among users
- Security and regulatory issues on prevalence of internet based data marts.
Emergence of Big Data and Data Lakes
Apart from data silos, the exponential growth of data from the internet became another challenge for data architects. Data quickly conformed to the 3Vs of big data with huge volume, velocity, and variety, eventually demanding a new system that could process massive amounts of data without slowing down as well as support a mix of data from structured to semistructured and unstructured data.
Data lakes were developed that stored the big data without needing to go through the rigorous ETL process as in Data warehouse and therefore offered fast access to data. Besides the required transformation could be done after ingestion and loading of data.
Google BigQuery and Amazon Redshift tried to solve the throughput and concurrency issues by adopting a MPP (massively parallel processing) approach towards data query processing. Snowflake however went to the bedrock and challenged the data architecture of the traditional systems.
It questioned the resource extensiveness in the data architecture of traditional technologies which required separate data modeling. Snowflake revamped the ideology and developed a single and unified data architecture that uses a single pipeline for both data warehouse and data lake solving the issues of workload and concurrency.
Understanding Data Architecture of Snowflake
When a company embarks on a data analytics journey, a major decision is whether to use a data warehouse or a data lake. Snowflake diminished this requirement by offering a unified data platform that could work both as a data warehouse and a data lake.
Snowflake’s data cloud innovates by using a single SQL query engine, supporting a limitless number of concurrent users, and maintaining a single copy of data across the data pipeline. Data architecture of Snowflake is based on four logical data zones as shown in the figure below.
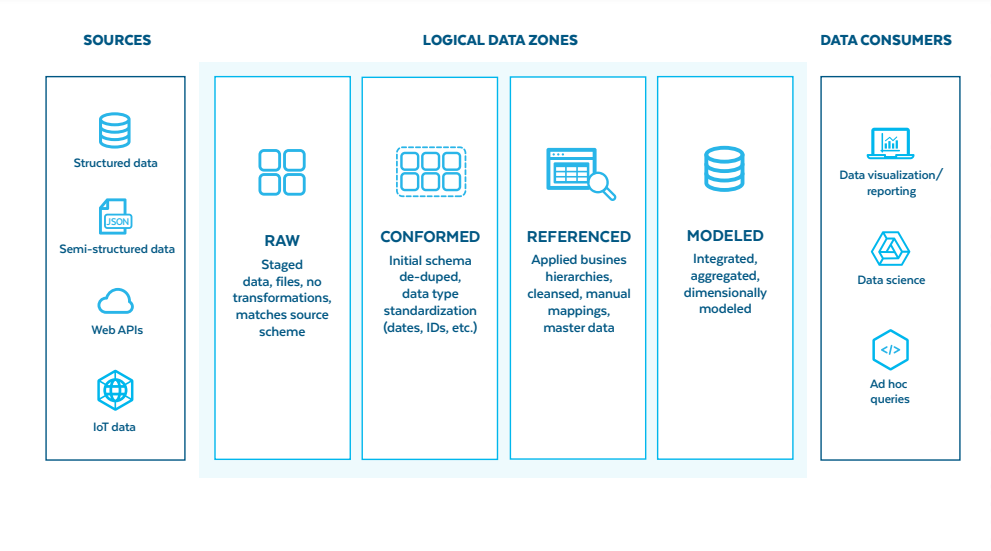
The ‘Sources’ block in the diagram displays big data sources that provide raw data in huge volume, variety, and velocity. The next block carries four stages and raw data is flowed in sequence.
The first stage is the ‘Raw Zone’ that contains raw data as it has arrived from the source system.
In the ‘Conformed Zone’, ‘Reference Zone’, and ‘Modeled Zone’ the raw data is cleansed and data types are set. The data is optionally converted from raw form to Snowflake’s columnar format. The data is organized to present the business processes, logic, and indicators. The output of the modeled zone is a clean, standardized, modeled, and integrated data that is accessible to BI, and Data Science users.
Before reaching to the modeled zone, the data from conformed zone could be sent to a company’s on-premise data lake in the form of Parquet files (rich columnar tables) in case when a company wants to use Snowflake only as an ETL pipeline.
Similarly, Snowflake also offers the flexibility to business users to use its data cloud as a query engine without needing to upload data on its cloud. This functionality would offer cost effective and efficient query processing on external tables using materialized view.
All the four zones represent the primary data platform of snowflake irrespective of the distinction of data warehouse and data lake. Snowflake offers loading of data in either raw form, or the Snowflake’s columnar format.
About Snowflake
Snowflake proudly calls them as the only modern cross-cloud SaaS platform around the globe. It’s built on top of Google Cloud, AWS, and Azure and offers the most flexible data analytics services under a single platform. Read out more on Snowflake’s unified platform in their official publication.